
硬件要求
Llama-2 模型的性能很大程度上取决于它运行的硬件。 有关顺利处理 Llama-2 模型的最佳计算机硬件配置的建议, 查看本指南:运行 LLaMA 和 LLama-2 模型的最佳计算机。
以下是 4 位量化的 Llama-2 硬件要求:
对于 7B 参数模型
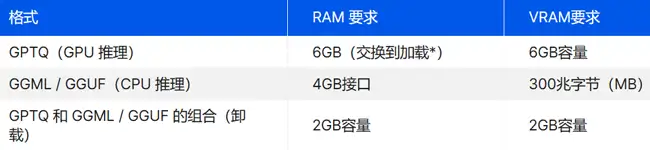
如果 7B Llama-2-13B-German-Assistant-v4-GPTQ 模型是你所追求的,你必须从两个方面考虑硬件。第一 对于 GPTQ 版本,您需要一个至少具有 6GB VRAM 的体面 GPU。GTX 1660 或 2060、AMD 5700 XT 或 RTX 3050 或 3060 都可以很好地工作。 但对于 GGML / GGUF 格式,更多的是拥有足够的 RAM。您需要大约 4 场免费演出才能顺利运行。

对于 13B 参数模型
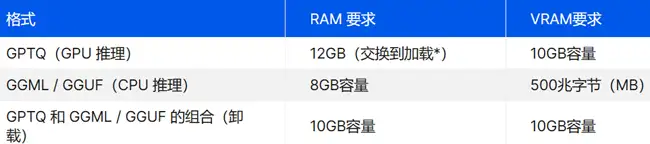
对于像 Llama-2-13B-German-Assistant-v4-GPTQ 这样更强大的型号,您需要更强大的硬件。 如果您使用的是 GPTQ 版本,则需要一个具有至少 10 GB VRAM 的强大 GPU。AMD 6900 XT、RTX 2060 12GB、RTX 3060 12GB 或 RTX 3080 可以解决问题。 对于 CPU 入侵 (GGML / GGUF) 格式,拥有足够的 RAM 是关键。您需要您的系统有大约 8 个演出可用来平稳运行。
适用于 65B 和 70B 参数模型
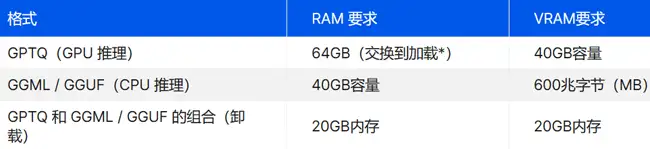
当您升级到 65B 和 70B 型号()等大型型号时,您需要一些严肃的硬件。 对于 GPU 推理和 GPTQ 格式,您需要一个具有至少 40GB VRAM 的顶级 GPU。我们说的是 A100 40GB、双 RTX 3090 或 4090、A40、RTX A6000 或 8000。您还需要 64GB 的系统 RAM。 对于 GGML / GGUF CPU 推理,为 65B 和 70B 型号提供大约 40GB 的 RAM。
内存速度
运行 Llama-2 AI 模型时,您必须注意 RAM 带宽和 mdodel 大小如何影响推理速度。这些大型语言模型需要完全加载到 RAM 或 VRAM,每次它们生成新令牌(一段文本)时。例如,一个 4 位 13B 十亿参数的 Llama-2 模型占用大约 7.5GB 的 RAM。
因此,如果您的 RAM 带宽为 50 GBps(DDR4-3200 和 Ryzen 5 5600X),您每秒可以生成大约 6 个令牌。 但是对于像每秒 11 个令牌这样的快速速度,您需要更多带宽 - DDR5-5600,大约 90 GBps。作为参考,像 Nvidia RTX 3090 这样的高端 GPU 有大约 930 GBps 的 带宽到他们的 VRAM。最新的 DDR5 RAM 可提供高达 100GB/s 的速度。因此,了解带宽是有效运行像 Llama-2 这样的模型的关键。

